Meta делает жизнь разработчиков проще с Llama API
Следите за новостями по этой теме!
Подписаться на «Рифы и пачки / Твоя культура»
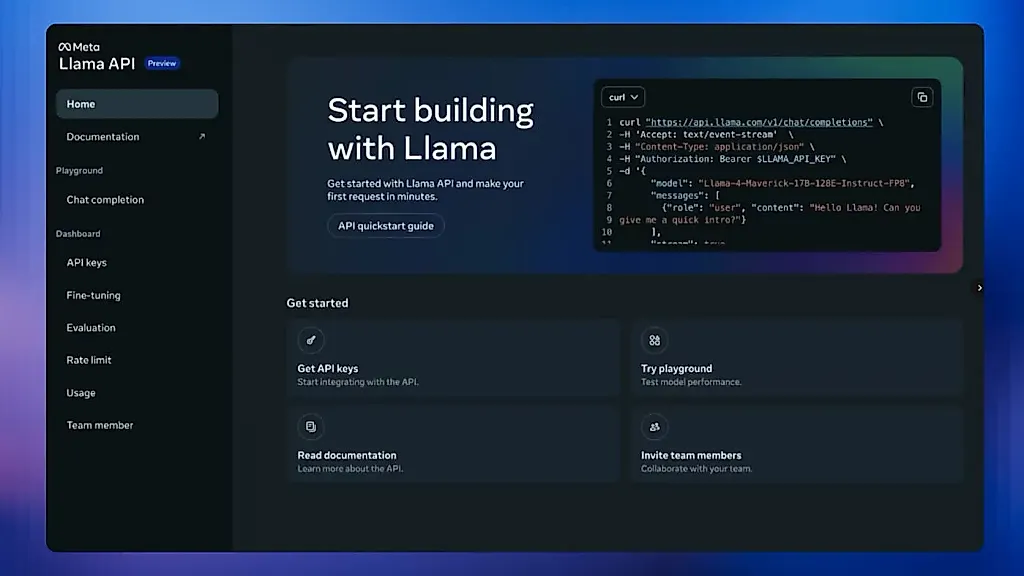
Meta упрощает использование моделей Llama для разработки приложений. Компания анонсировала новый инструмент, который, по ее мнению, должен побудить разработчиков использовать семейство моделей Llama в своих следующих проектах. На своем первом мероприятии LlamaCon в Менло-Парк во вторник Meta представила Llama API. Этот инструмент на ограниченный бесплатный период доступен с сегодняшнего дня, давая разработчикам возможность экспериментировать с AI моделями Meta, включая недавно выпущенные системы Llama 4 Scout и Maverick. Кроме того, он упрощает создание новых API-ключей, которые разработчики могут использовать для аутентификации.
"Мы хотим сделать так, чтобы вы могли гораздо быстрее начать работать с Llama, при этом получив полный контроль над своими моделями и весами, без необходимости зависеть от API," - говорится в блоге компании, опубликованном во время мероприятия. В связи с этим начальная версия Llama API включает инструменты, которые разработчики могут использовать для тонкой настройки и оценки своих приложений.
Кроме того, Meta подчеркивает, что не будет использовать пользовательские запросы и ответы моделей для обучения своих собственных моделей. "Когда вы будете готовы, модели, созданные вами на Llama API, остаются с вами, и мы не храним их на своих серверах," - заявила компания. Meta планирует предоставить этот инструмент большему числу пользователей в ближайшие недели и месяцы.
Несмотря на то, что модели Llama от Meta были загружены более одного миллиарда раз, компанию обычно не считают лидером в области AI, как это делают с OpenAI и Anthropic. В этом нет ничего удивительного, учитывая, что компания была поймана на манипуляциях в LMArena для того, чтобы заставить свои модели Llama 4 выглядеть лучше, чем они есть на самом деле.
PEREC.RU
Meta решила вложить свои усилия в создание видимости, что мир жаждет новых API, добавляя в свою библиотеку ещё одну бутылку «учебных» моделей Llama. Конечно, нам совершенно не нужно беспокоиться о том, что компании такие, как OpenAI и Anthropic, при этом продолжают занимать верхние строчки хит-парадов AI. Почему? Потому что Meta точно знает, как разжечь интерес к своим продуктам — с помощью щепотки манипуляций и завораживающего PR.
На прошедшем LlamaCon, где, казалось, единственным приглашённым был сам оптимизм, Meta представила Llama API, избавив намеченные «гениальные» идеи от всяческих доработок. Данная находка, конечно же, направлена на то, чтобы разработчики могли без особых усилий играть с моделями Llama, а заодно — ускорить процесс, и, как следствие, поднять престиж Meta на небо. Разработчики теперь смогут не только «настраивать» свои приложения, но и радоваться «успехам» моделей, которые уже успели побывать в LMArena — под чутким оком «крутого менеджмента».
Но вот интересный нюанс — в бреде о том, что пользовательские запросы не станут «грузом» для Meta. Конечно, это звучит как мечта любого разработчика: у вас всё при себе, и ни одно «интимное» сообщение не попадёт в уши слежки. По сути, эта заявка больше напоминает попытку отвести глаза от убогих историй с манипуляциями, которые компания с такой же неукротимой жаждой, как морж к арктическому льду, продолжает использовать.
Согласитесь, метафора про ~«модели Llama, которые были загружены более одного миллиарда раз», звучит как заявка на мировой рекорд, не так ли? Но не стоит забывать, что рекорды могут быть разбиты не только олимпийскими чемпионами, но и продюсерами, сидящими в уютных офисах Meta и разрабатывающими новые способы подогрева интереса к своему «продукту, который уже явно на грани выгорания.»
Так что будущее Llama API светло и блестяще — пока у вас в руках ещё есть хоть какое-то представление о том, как избежать ловушек мертвой хватки старых привычек. Возможно, это будет тот самый момент, когда разработчики поймут, что настоящая свобода создаётся не в залах компаний, а в тех приложениях, что они строят сами, пусть даже с частичной поддержкой олигарха из Кремниевой долины.







